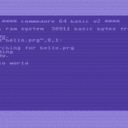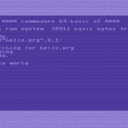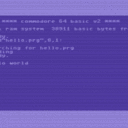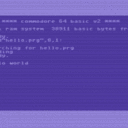
Hi, ich denke der Thread-Titel sagt schon, worum es geht.
Die Idee für diesen Thread kam mir in einem anderen Thread mit dem Titel
Opcode-Dispatchmethoden bzw. Indirekte Sprünge
Ich zitiere einen Post teilweise von dort hierher zum Start:
 Zitat von M. J.
Zitat von M. J.Ja, gerne. Das Thema interessiert mich auch. Habe selber vor einiger Zeit mal eine virtuelle Maschine für einen hypothetischen 16-Bit-Risc-Prozessor (Zwei-Register-Befehle mit 16 Registern, d. h. 4 Bit pro Register) geschrieben, die einigermaßen schnell läuft.
...
Von der extremen RISC-Philosophie bin ich letzten Endes wieder abgewichen, da so die Integration von Immediate-Konstanten (auch für Sprungbefehle bzw. Unterprogrammaufrufe) programmtechnisch einfach zu aufwendig und zu langsam wurde. Nichtsdestoweniger verbrauchen die allermeisten Befehle nur 16 Bit, da es für die häufigen MOVE-, ADD- und CMP-Befehle Kurzformen gibt. Die Einführung dieser Kurzformen war auch der Grund, wieso ich keine 3-Register-Befehle verwende, da sie a) nur selten wirklich gebraucht werden, aber b) viel Platz in der ISA veranschlagen.
Ich habe vor allem deshalb 3 Register Befehle genommen, damit man viele Befehle synthetisieren kann, wie ein MOV als ADD r3, r4, r0 (r0 immer 0) = MOV r3, r4
usw.
Ich denke, du hast dafür eigene Befehle?