
[Externes Medium: https://youtu.be/oTaND5Gg3po]
Jetzt warte ich nur auf eine OpenGL-kompatible 3D-Beschleuniger-Karte für den C64. ![]()
Du bist in Begriff, Forum64 zu verlassen, um auf die folgende Adresse weitergeleitet zu werden:
Bitte beachte, dass wir für den Inhalt der Zielseite nicht verantwortlich sind und unsere Datenschutzbestimmungen dort keine Anwendung finden.


[Externes Medium: https://youtu.be/oTaND5Gg3po]
Jetzt warte ich nur auf eine OpenGL-kompatible 3D-Beschleuniger-Karte für den C64. ![]()

Aber ich hoffe, dass irgendwann auf europäischer Ebene Linux als Standard-OS (und FOSS für Software insgesamt) für Verwaltungen etc. vorgegeben wird. Das wäre dann DIE Chance, Desktop-Marktanteile zu generieren. Aber das hoffe ich schon recht lange.
Diese Hoffnung teile ich von Herzen, auch wenn ich eher skeptisch bin, ob es je so kommt.

Ich verfolge das mit den Mac OS Versionen nicht, weil mich Apfel am Arsch lecken kann, seitdem sie auf PC-geräten (ja, ein Imac ist nichts anderes als ein PC) diese Philosophe des Schmeißweg fahren
Ja, das ist unglaublich unsympathisch. Ich finde, hier könnte die EU wirklich wieder einmal ein wohltuendes Werk tun und schlichtweg diese Praxis (wenn geht rückwirkend) verbieten.
 Alles anzeigen
Alles anzeigen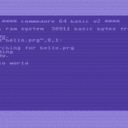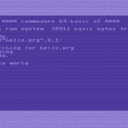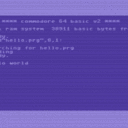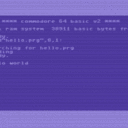
Jetzt kommen wir der Sache schon näher. Die zwei Bytes sind die Lade-Addresse? Ich verwende plain files, ohne prg-Zusatz, aber wenn ich dich richtig verstehe, sind das trotzdem prg files.
Der PRG-Zusatz beschreibt nur den Typ der Datei, ist aber kein Bestandteil der Dateinamens. Per Konvention wird bei PRG-Dateien davon ausgegangen, dass die ersten beiden Bytes die Ladeadresse darstellt. So wird das von LOAD/SAVE gehandhabt. Aber halten muss man sich daran nicht. USR- und SEQ-Dateien sind gleichwertig, aber hier ist die Konvention nicht vorhanden und Dateien dieses Typs werden auch von LOAD ignoriert.
Ich gehe einmal davon aus, dass die gar nicht benötigt werden? OK, man soll mit solchen Annahmen immer sehr vorsichtig sein, aber Durex-Forth wird wohl selbst am besten wissen, wo es die hin lädt.
Würde ich auch meinen.
Wenn ich ein C-Programm schreibe, das mir auf dem PC die beiden Bytes rausnimmt, sie sich merkt, und dann wieder hinzufügt, und wenn ich es schaffe, das an der richtigen Stelle in den VSCode reinzuklemptnern, wäre das schon sehr bequem. Nur weiß ich halt auch nicht so gut, wie man das dort macht. Aber ich kann ja einmal suchen gehen. Vielleicht kann man dort ja Filter und Pipes verwenden.
Ja, sofern man sich das überhaupt merken muss. Wer weiß, ob die ersten beiden Bytes dann nicht nur als Platzhalter dienen, deren Inhalt ohnehin nicht relevant sind.
Mit externen Tools in einer Filter-Kette, wird man die ersten beiden Bytes sicherlich entfernen können und dann nach dem Editieren hinzufügen können.
Für mich reicht hier immer ein unter Windows portiertes Perl (wird vermutlich mit jeder Scriptssprache so irgendwie gehen). Das kann man dann ja auch in ein BAT- oder PS1-Script verpacken, um das strukturierter zu machen ...
Mein Ziel ist es, das irgendwie in VSCode zu integrieren. Aber ob ich das je schaffe, steht in den Sternen. ![]()
Vielleicht passiert da irgendwas von wegen Unicode? Denn die anderen sind lesbar wie zuvor.
Der Bytestream wird als wohl als UTF-16 interpretiert (UTF8 wäre ja für Codes <128 ziemlich ASCII-konform). Du musst dem Editor wohl sagen, dass er das "nur" als Plain-ASCII (oder wenn er das kann als PETSCII) oder halt eine andere 8-Bit-Zeichencodierung. Gegebenenfalls muss man halt auch diverse Zeichen hin-her-konvertieren (um von/zu PETSCII zu kommen).
Jetzt kommen wir der Sache schon näher. Die zwei Bytes sind die Lade-Addresse? Ich verwende plain files, ohne prg-Zusatz, aber wenn ich dich richtig verstehe, sind das trotzdem prg files. Ich gehe einmal davon aus, dass die gar nicht benötigt werden? OK, man soll mit solchen Annahmen immer sehr vorsichtig sein, aber Durex-Forth wird wohl selbst am besten wissen, wo es die hin lädt.
Wenn ich ein C-Programm schreibe, das mir auf dem PC die beiden Bytes rausnimmt, sie sich merkt, und dann wieder hinzufügt, und wenn ich es schaffe, das an der richtigen Stelle in den VSCode reinzuklemptnern, wäre das schon sehr bequem. Nur weiß ich halt auch nicht so gut, wie man das dort macht. Aber ich kann ja einmal suchen gehen. Vielleicht kann man dort ja Filter und Pipes verwenden. Schaumamal. ![]()
Durex-Forth hat aus meiner Sicht einen entscheidenden Nachteil, nämlich die Inkompatibilität seines File-Formats. Es ist tatsächlich nicht möglich, z.B. aus dem VICE heraus Files auf einer virtuellen 1541 in eimem Directory des File-Systems zu speichern, und die dann einfach mit einem PC-basierten Editor zu bearbeiten. Genau das wäre aber eine enorme Erleichterung, da der vi-clone "v" zwar grundsätzlich funktioniert, aber nicht perfekt. Er neigt dazu, irgendwann den Text nicht mehr korrekt darzustellen. Editierung und Text sind dann "out of sync". Während man meint, eine Zeile zu editieren, zerstört man sich in Wirklichkeit eine andere. Hier wäre die Verfügbarkeit ausgereichter Text-Editoren wirklich angenehm.
Ahso? Wie speichert DurexForth denn das ab? Witzig, ich hab mir bei meinem 816er-Forth auch damit geliebäugelt, einen minimalistischen VI-Clone zu machen. Die Idee scheint verbreitet zu sein. Aber hat sich noch nicht verwirklicht. Naja, da kann ich mir das mal bei DurexForth mal ansehen ...
Ich verwendet hier "plain" PRG-Dateien (sogar die ersten beiden Bytes, wo normalerweise die Ladeadresse steht, werden als "Inhalt" gesehen), die ich unter Linux als normale Textdateien editiere und dann mit etwas umwandeln (Newline, Tab, Kleinschreibung) als PRG-Dateien erstelle, was dann in ein Image kommt.
Mit früheren Durex-Forth-Versionen ist das noch gegangen. In 5-0-0 ist da nur Bytesalat zu sehen. Oder warte, ich schau zur Sicherheit noch einmal nach!
OK, jetzt bin ich ganz verwirrt. Eines meiner Files zeigt sich so:
ꀁ‱മ䕒啑剉⁅佃偍呁㈍⸠刍充䥕䕒匠剔䍕ൔ″മ䕒啑剉⁅剁䅒൙‴മ䕒啑剉⁅呚䉁㔍⸠刍充䥕䕒䜠塆䕒啑剉⁅䱔䌭䕒呁ㄍ‰∮䄠剒奁䕔呓•䕋⁙剄偏䄍剒奁䕔呓䕈൘ㄍ‱∮䠠剉卅䕔呓•䕋⁙剄偏㨍䠠剉卅䕔呓†䥈䕒†〱䌠剌佃ൌ㈠〰〠䐠൏††⁉啄⁐䱐呏䰠住䬠奅䰠剏卅㬍㈱⸠䠍剉卅䕔呓㌱⸠佃䕄㸠㠾䴠䉓䰠䅄堬䰠䉓匠䅔堬〠䰠䅄⌬䴠䉓匠䅔堬删協ബ久ⵄ佃䕄㐱⸠›䕗䝉呈⠠堠夠䠠䝉䉈呙孅⩘嵙⤠⠠堠夠⤠⨠⠠堠夠⤠㸠㠾⠠删䠽䝉孈⩘嵙㸾‸ഩ഻ㄍ‵മ㨍㌠䷄偁⠠堠夠娠ⴠ员夠⁔ഩ†⁛䕈⁘൝†啄⁐刾⠠堠夠娠删›ⴭ娠⤠⼠⠠ⴠ⁘⽙⁚㩒娠⤠尠䐠偕⸠•⽙⁚•മ†〸⬠⠠堠夠⁔㩒娠⤠尠䐠偕⸠•呙∠⸠匠䅗⁐
ⴭ夠⁔⁘㩒娠⤠删‾
ⴭ夠⁔⁘⁚ഩ†
ⴭ夠⁔⽘⥚尠䐠偕⸠•⽘⁚•മ†〸⬠⠠ⴠ呙堠⥔尠䐠偕⸠•员∠⸠匠䅗⁐
员夠⁔ഩ഻㨍䜠呅促剏卄⠠☠䱔䤠ⴠ⁘⁙⁚ഩ嬠⸠•㘱ㄮ•൝†啄⁐⁘⁀
否孌嵉吠孌嵉堮⤠嬠⸠•㘱㈮•൝†坓偁⠠吠孌嵉堮☠䱔䥛⁝ഩ†⁛∮ㄠ⸶∴崠䐠偕夠䀠⠠吠孌嵉堮☠䱔䥛⁝䱔䥛⹝⁙ഩ†⁛∮ㄠ⸶∵崠匠䅗⁐
䱔䥛⹝⁘䱔䥛⹝⁙否孌嵉⤠嬠⸠•㘱㘮•൝†⁘⁀
䱔䥛⹝⁘䱔䥛⹝⁙䱔䥛⹝⁚ഩ഻ㄍ‷∮吠䵉䱅义큅佌≔䬠奅䐠佒㨍吠䵉䱅义큅佌ൔ†⁛䕈⁘൝†䥈䕒†〱䌠剌佃ൌ†〲〠䐠൏††⁜⁉മ††⁉䥔䕍䥌䕎堠尠䀠䐠偕唠മ††⁉䥔䕍䥌䕎夠尠䀠䐠偕唠മ††⁉䥔䕍䥌䕎娠尠䀠䐠偕唠മ††剃†㌠䷄偁尠⸠•员•啄⁐⹕††⁜坓偁⸠•呙•啄⁐⹕††⁜坓偁†倠佌ൔ††剃†尠䬠奅䐠佒†佌偏䬠奅䐠佒†佌䕒഻ㄍ‸മ名䵉䱅义큅佌ൔ佌䕒S
Vielleicht passiert da irgendwas von wegen Unicode? Denn die anderen sind lesbar wie zuvor.
Jetzt habe ich wirklich ein Gerücht gestreut, tut mir leid!
Update: Wenn du eine Lösung für das Ding mit den ersten zwei Bytes hättest, köntnest du sie mir dann verraten? Danke!
So - Erfahrungen mit Durex-Forth bis jetzt:
Abgesehen von der hier schon diskutierten kleinen Unkompatibilität bin ich an sich sehr glücklich über diese Implementierung, die wirklich viel kann. Über FORTH selbst brauche ich nicht viel sagen, das ist für kleine Berechnungsprogramme sehr gut, für Anwendungen mit komplexeren Datenstrukturen sehr gewöhnungsbedürftig und auch schwierig. Aber da bin ich vielleicht noch zu sehr Anfänger, das soll jetzt kein Werturteil sein.
Durex-Forth hat aus meiner Sicht einen entscheidenden Nachteil, nämlich die Inkompatibilität seines File-Formats. Es ist tatsächlich nicht möglich, z.B. aus dem VICE heraus Files auf einer virtuellen 1541 in eimem Directory des File-Systems zu speichern, und die dann einfach mit einem PC-basierten Editor zu bearbeiten. Genau das wäre aber eine enorme Erleichterung, da der vi-clone "v" zwar grundsätzlich funktioniert, aber nicht perfekt. Er neigt dazu, irgendwann den Text nicht mehr korrekt darzustellen. Editierung und Text sind dann "out of sync". Während man meint, eine Zeile zu editieren, zerstört man sich in Wirklichkeit eine andere. Hier wäre die Verfügbarkeit ausgereichter Text-Editoren wirklich angenehm.
Ich mache es derzeit aus leidvoller Erfahrung so, dass ich parallel immer auch in PC-Files mit editiere, und dann notfalls deren Inhalte über die "paste"-Funktion des Vice in ein File einfügen kann, wenn ich ein kapuittes File rekonstruieren muss.
Ich denke, sobald der "v" ausgereift ist, ist das kein Problem mehr, und wer weiß, vielleicht kommt ja von den Autoren irgendwann auch Hilfe bezüglich der externen Editierbarkeit.
Mein Fazit: Immer noch empfehlenswert, wenn auch mit leichten Mängeln.
 Alles anzeigen
Alles anzeigenGerade eben bei Wer wird Millionär hätte ich mir an den Kopf fassen können.
Die Frage lautete in etwa "Wer war Mitte der 80er Marktführer und ging 10 Jahre später pleite?"
Die Antworten waren Commodore, Kodak, Nokia und Schlecker.
Der hat den Publikumshocker verwendet, 3 standen auf aber keiner wusste es sicher.
Einer der dreien hat aber zu Kodak tendiert (Die anderen Commodore), weil der Marktführer war ja IBM...
Bei der Frage nach seinem Beruf meinte er, er komme aus der IT.
Er hat dann zum Schluss Commodore geraten.
Also totales Schwein gehabt und unverdient gewonnen. ![]()
Bloß eines verstehe ich nicht: Es war ja schon einmal runtime. Wieso die Exkursion in dieser Version?
Github-Change zeigt die jüngste Korrektur.
Was heißt hier "runtime"? Gemeint ist, dass es irgendwann einmal schon nicht nur zu Compile-time funktioniert haben soll (zur Interpreting-time), oder? Scheint schon 2019 zurück liegen, wo die Reduktion auf Compile-time gemacht wurde: Github: base.fs
Wohl deswegen, weil S" keine transienten Puffer verwendet hat (nur rutimentär implementiert war), also mehrere Angaben nicht möglich waren. D.h. es hat nicht so funktioniert, wie es laut Standard vorgesehen ist. Der String wird immer am Beginn des freien Dictionary-Speichers angelegt und mehrfach angegebene Strings überschreiben sich ...
Oh ja, danke, das ergibt Sinn! Das heißt, bis jetzt war es eine kaputte Krücke, die Beschränkung auf Compile-Time ist sowas wie ein Baustellen-Zaun, um die Reparatur zu ermöglichen, und sobald das repariert ist (was es mittlerweile wohl schon ist), funktioniert dann auch die Runtime.

Das Witzige daran ist ja, dass es ansonsten für die Runtime noch .( .. ) gibt, das aber den String sofort ausgibt. Warum der speicher-Mechanismus in dem Fall zur Runtime geht und sonst gar nicht, ist mir ein Rätsel.
Weil es direkt konsumiert wird, womit es einfach in den Textpuffer geladen werden kann, ohne dass es die Erwartung gibt, dass der String ne Weile überlebt (und zum Beispiel erstmal zwei Strings eingelesen werden, mit denen dann gearbeitet werden soll, aber leider nur noch einer übrig ist).
Man kann sich ja ein runtime s" selbst basteln, wenn man unbedingt will, und dann weiß man wenigstens, wie die Strings abgelegt werden (und kann das Verhalten nach Bedarf anpassen)
OK, danke, wieder was gelernt.
Gut, ich versuch das einmal, vielleicht gelingt es mir. Ich bin eher ein Anfänger in FORTH (merkt man eh ![]() ), aber das ist sicher eine gute Übung wie schon das cat heute, von dem ich viel gelernt habe.
), aber das ist sicher eine gute Übung wie schon das cat heute, von dem ich viel gelernt habe.
Bloß eines verstehe ich nicht: Es war ja schon einmal runtime. Wieso die Exkursion in dieser Version?
Aber so generell wundert mich trotzdem, dass die String-Definition mit dieser Version auf einmal compile-time-only geworden ist. Ist das überhaupt Standard-Konform?
.. OK, das ist eher eine Frage für
Da geht es weniger um Compile-Time, sondern, wo der Parameter angegeben wird. Üblicherweise müsste ein Parameter in Postfix-Notation angegeben werden. Nur wenn man einen Dateinamen *nach* dem Kommando haben möchte, muss man sich eigentlich einem Parser-Konstrukt beanspruchen. Das ist aber im eigentlichen Sinne nicht der "Forth-Spirit", sondern spiegelt die Erwartungshaltung aus anderen Umgebungen wider.
Es müsste eigentlich ." Datei" CAT. Das Problem damit ist, dass man hier nur einen String angeben kann, da der immer am gleichen Ort liegt. Damit mehrfache Parameter möglich sind, gibt es laut Standard S" Datei1" S" Datei2" KOMMANDO, wo die Strings jeweils in entsprechende (ev. zirkulär) verwaltete Puffer gelagert werden. Und S" ist explizit für den interaktiven Gebrauch gedacht. Zumindest laut Forth-2012-Standard. Käme mir komisch vor, wenn das ausgerechnet bei DurexForth nicht so sein sollte.
Ja eben, mir auch. Übrigens danke für die Aufklärung, wieder was gelernt. Und jetzt zum Zitat:
s" ( — caddr u )
Define a string. Compile-time only! Example: s" foo".
in diesem File: durexforth-v5.0.0-operators-manual.pdf auf Seite 23 oben "Strings".
Das Witzige daran ist ja, dass es ansonsten für die Runtime noch .( .. ) gibt, das aber den String sofort ausgibt. Warum der speicher-Mechanismus in dem Fall zur Runtime geht und sonst gar nicht, ist mir ein Rätsel.
Nachtrag: Ich sehe grade, dass die spezialform parse-name sogar noch besser ist, weil auf einer UNIX-Plattform man ja i.a. auch keine Anführungszeichen benutzt. Vermutlich wirds für 1541-Files dann blöd, wenn die Spaces enthalten, aber darüber denke ich noch nach. Vielleicht ein Wort schreiben, das vom ersten Zeichen her den String anders benutzt, aber das ist einmal SF, vorerst freue ich mich über ein simples cat für die einfachen Fälle.
Wieso eigentlich? Gerade bei Unix muss auch doppelte oder einfache Anführungszeichen verwenden, um die besondere Bedeutung von Metazeichen und Trennzeichen zu unterdrücken. Das hängt auch da vom jeweiligen Anwendungfall ab.
Unter Forth ist es üblich Strings explizit in doppelte Anführungszeichen zu führen. Metazeichen in dem Sinne gibt es nicht, nur etwaige Trennzeichen (Steuerzeichen und Leerzeichen etwa bei WORD).
PARSE-NAME ist ja eigentlich nur für die typischen Wortnamen gedacht, verhält sich aber neutraler als das klassische WORD (abgesehen auch vom anderen Rückgabeformat).
Du hast völlig recht, aber so ist es erst einmal viel einfacher geworden. ![]()
Nachtrag: Wollte ich es UNIX nachmachen, müsste ich als Erstes die Pipe nachbilden, und das wäre einerseits absolut geil - aber andererseits wäre ich damit erst einmal ganz fürchterlich überfordert. ![]()
![]() (.. und der C64 vermutlich auch.)
(.. und der C64 vermutlich auch.)
OK, hier das Ergebnis:
Es funktioniert soweit (und viel schneller als ich dachte), ich bin aber nicht sicher, ob nicht eventuell ein Character am Schluss doppelt ausgegeben wird wenn st<>0 ist, weil st ja erst danach gecheckt wird. Und ob das "guter Code" oder "Stil" ist, wage ich auch nicht zu sagen. Falls jemand daran herummäkeln möchte, bitte gern, ich kann daraus ja nur lernen! 
![]()
Alles anzeigenWenn du ohne Leerzeichen im Dateinamen auskommst, wäre parse-name eine option: "parsename 1234foo9876 type" gibt den Begriff in der Mitte aus.
Systemworte wie "include" benutzen dieselbe Methode.
Variante, die auf " endet: 34 parse 12345 foo" type (34 entspricht ")
Damit würde cat wohl so anfangen (Konvention bei Worten, die bis " lesen: der Name endet auf ", siehe s" foo")
: cat" 34 parse ( string-addr string-länge)
...
und würde aufgerufen: cat" datei, die gecattet werden soll"
Ah, super, danke, das ist ja einmal ein Tip! ![]()
Muss ich noch verstehen lernen, aber das werde ich. ![]()
Und sicherstellen, dass zu dem Zeitpunkt mit "decimal" die Zahlenbasis 10 ist.
Auch dafür danke, aber das wird hoffentlich mit der Definition eines Wortes gegessen sein? Hoffe ich jetzt einmal. ![]()
Aber so generell wundert mich trotzdem, dass die String-Definition mit dieser Version auf einmal compile-time-only geworden ist. Ist das überhaupt Standard-Konform? ![]() .. OK, das ist eher eine Frage für
.. OK, das ist eher eine Frage für ![]()
![]()
Nachtrag: Ich sehe grade, dass die spezialform parse-name sogar noch besser ist, weil auf einer UNIX-Plattform man ja i.a. auch keine Anführungszeichen benutzt. Vermutlich wirds für 1541-Files dann blöd, wenn die Spaces enthalten, aber darüber denke ich noch nach. Vielleicht ein Wort schreiben, das vom ersten Zeichen her den String anders benutzt, aber das ist einmal SF, vorerst freue ich mich über ein simples cat für die einfachen Fälle. ![]()
Hallo Leute,
eine Frage an DurexForth-Kenner: in der neuen 5.0-Version steht im Manual explizit dieses hier:
Meine wohlüberlegt-rationale Frage dazu:![]() HILFE verdammt, wie mach ich einen String zur run-time???
HILFE verdammt, wie mach ich einen String zur run-time??? ![]()
Hintergrund: Ich will nämlich ein "cat" implementieren, das mir ein File öffnet, und char-weise ausgibt. Da wärs schon geil, den Filenamen in echtzeit angeben zu können. ![]()
Obwohl - vielleicht reichts auch ohne Anführungszeichen irgendwo, da muss ich mich noch hineinstürzen. Aber so grundsätzlich wär so eine Möglichkeit, Strings in der Kommandozeile anzugeben, schon nett, nicht?

Gut. Neuere VICE-Versionen benutzen das in der Online-Doku angegebene Namensschema (inkl. Versionsnummern im Namen) für die ROM-Dateien, Du wirst ein ähnliches Problem wie jetzt also beim nächsten VICE-Upgrade wieder haben.
Ich dachte 3.6.1. wäre hinreichend neu. Zudem hat mir die flatpak-Version die Dinger zuvorf hin installiert (ich hab sie bloß gesichert und verschoben), also insofern schon sehr merkwürdig. Aber egal, ich habe jetzt ein Directory mit beiden Benennungen, das passt in Zukunft auf jeden Fall. ![]()
Dort muss der Depp sie doch finden?
Ich ruf dann x64sc mit strace auf und schau auf welche Verzeichnisse da Ding zugreift. ... bevor ich noch in Foren und Google herumsuch.
Schau ich mir auf jeden Fall auch noch an, ziemlich guter Tip, danke!
Update: Selbes Resultat.Ja und was sagt strace? Das kann nicht magisch den Fehler beheben, sondern sagt Dir nur, wo welche Dateien erwartet/geöffnet werden.
Oweia, du hast ja völlig recht, das ist faszinierend:
access("/usr/bin/DRIVES/d1541II", R_OK) = -1 ENOENT (No such file or directory)
access("/usr/share/vice/DRIVES/d1541II", R_OK) = -1 ENOENT (No such file or directory)
Der Depp sucht nach völlig anderen File-Namen als angegeben. Ich mach einen Versuch mit umbenennen.![]()
![]()
![]() BINGO
BINGO![]()
![]()
![]()
Jetzt findet er es!
Ja, ich war gestern bereits ein wenig müde, danke JeeK für den Hinweis und 1570 für den zusätzlichen Fußtritt in die richtige Richtung! ![]()

Achso, ich glaub ich hab mich da vertan. Ist garnicht die Flatpak version. Wo kann ich das sehen, in dem Screenshot ist davon nichts zu lesen.
Ich hab die ursprünglich auf Flatpak gehabt, aber es dann geändert, weil ich von dort das binary nicht durch Visual Studio Code starten konnte. Aber ich werds noch einmal probieren, ist einen Versuch wert. Ich berichte es dann hier, sobald erledigt. Danke für den Tip!
 Alles anzeigen
Alles anzeigenIch werfe mal den folgenden Link in den Ring:
https://build.opensuse.org/package/show/home:strik/vice
bzw. zum Download der Binaries/Einfügen der Paketquellen (je nachdem, was gewünscht ist):
https://software.opensuse.org/…home%3Astrik&package=vice
Da wird (beinahe) täglich die aktuelle Version von VICE gebaut und als .DEB-Pakete angeboten. Diese basieren auf den Debian-Paketen, enthalten aber auch die nötigen ROMs.
"Beinahe täglich" deshalb, weil der Automatismus (noch) manchmal versagt...
Vielen Dank, das ist ja ein Juwel! ![]() Ich schau einmal ob das funzt, und geb dir dann auch Info.
Ich schau einmal ob das funzt, und geb dir dann auch Info. ![]()
![]()

Ich baue mir meinen VICE selber, daher kann ich nicht mit Erfahrungen zu fertigen Paketen dienen.
Das kommt bei mir gleich nach sich das eigene Laserschwert selbst basteln. ![]()
OK - es soll offenbar nicht sein. ![]() Hab alles gelöscht und neu installiert. Ergebnis:
Hab alles gelöscht und neu installiert. Ergebnis:
DriveROM: Error - 1540 ROM image not found. Hardware-level 1540 emulation is not available.
DriveROM: Error - 1541 ROM image not found. Hardware-level 1541 emulation is not available.
DriveROM: Error - 1541-II ROM image not found. Hardware-level 1541-II emulation is not available.
DriveROM: Error - 1570 ROM image not found. Hardware-level 1570 emulation is not available.
DriveROM: Error - 1571 ROM image not found. Hardware-level 1571 emulation is not available.
DriveROM: Error - 1581 ROM image not found. Hardware-level 1581 emulation is not available.
DriveROM: Error - 2000 ROM image not found. Hardware-level 2000 emulation is not available.
DriveROM: Error - 4000 ROM image not found. Hardware-level 4000 emulation is not available.
DriveROM: Error - CMDHD ROM image not found. Hardware-level CMDHD emulation is not available.
DriveROM: Error - 2031 ROM image not found. Hardware-level 2031 emulation is not available.
DriveROM: Error - 2040 ROM image not found. Hardware-level 2040 emulation is not available.
DriveROM: Error - 3040 ROM image not found. Hardware-level 3040 emulation is not available.
DriveROM: Error - 4040 ROM image not found. Hardware-level 4040 emulation is not available.
DriveROM: Error - 1001/8050/8250 ROM image not found. Hardware-level 1001/8050/8250 emulation is not available.
DriveROM: Error - D9090/9060 ROM image not found. Hardware-level D9090/9060 emulation is not available.
Drive: Finished loading ROM images.
Ist offenbar ein Kurs im Frustration Aushalten. ![]() und irgendwann wirds schon wieder gehen. Pfeif drauf, mach ich halt derweil was Anderes, hab eh noch genug zu tun.
und irgendwann wirds schon wieder gehen. Pfeif drauf, mach ich halt derweil was Anderes, hab eh noch genug zu tun. ![]()
![]()
Ach ja, und DANKE allen Antwortern und Antworten!