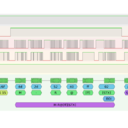
Folgendes Problem gibt es auch noch:
Innerhalb des SID gibt es ja - wie erwähnt - eine Abbildungsvorschrift*, die aus den 12-Bit (2^12 == 4096) Werten
des LFSR die 8-Bit (2^8 == 256) Werte des Registers zum auslesen macht.
Käme in einer Stichprobe aus dem gesamten 12-Bit Eingangswertebereich jede Zahl nur 1x vor (also von 0-4095
gezählt), würde jeder Ausgangwert 2^4 (=16) mal am Ausgang erscheinen.
Leider erzeugt das LFSR prinzipbedingt aber keine 0x000 als Eingangszahl. D.h. die Zahl 0x00 wird am Ausgang
daher mit einer etwas geringeren Wahrscheinlichkeit (15/16 = 0.9375) erzeugt, als die restlichen 255 (16/16 = 1.0) Zahlen!
*ps: Das klingt spannender als es ist: Es werden lediglich 8 bestimmte Bits des 12Bit Werts ausgelesen; die restlichen Bits
spielen keine Rolle für den Ausgangswert.